No more Language Salad: Streamlining Multi-Lingual Data in Web Analytics with LLMs
How Gemini can make (not only) Adobe Analytics report data more useful
I call it Language Salad: Reports full of terms, URLs or labels from all the languages a site offers. A mix that turns analyses into headaches and makes clean segments or report filters near-impossible. Every client of mine chews on Language Salad with varying frequency, no matter how monolingual their Data Layer. But there is a sweetener now. Spoiler: It’s NOT a translation API.
Imagine I wrote every sentence of this article in another language. Könnten Sie mir dann noch folgen? Czy państwo w ogóle zrozumieliby cokolwiek? Seguro que su asistente inteligente le ayudaría. Però si ho faig per a cada frase? Je suis sûr que ça vous fatiguerait bientôt. Еще хуже, если использую нелатинские символы. 还是象形文字? (I don’t know Mandarin, so no idea if that last sentence makes any sense… 😅).
Welcome to the dizzying feeling when analyzing data wrapped in Language Salad!

Let me start with a confession:
Every single one of my clients has to eat some Language Salad.
A multi-lingual site can be great for the user experience (in my experience, it is usually the opposite, because multi-lingual sites are so often poorly implemented). But it is a challenge for Analytics.
The goal of any tracking setup is, of course, to track everything in a single language only to avoid Language Salad in the first place. In practice however, this is nearly impossible to accomplish to a satisfying degree. Even if your website developers work diligently to provide everything in the Data Layer in a single language, there will always be cases where language canonicalization is too tedious or not important enough to warrant resources.
Some examples where you want language-independent data in Analytics
- product data, e.g., names and categories
- page names / URL paths: I want to analyze a piece of content (e.g., an article) independent from the language it was viewed in
- content tags
- links or text labels in navigation menus
- URLs or texts of links to other pages
- names (“size”) and values (“medium”) of search filters
- form subjects
- user input (search, qualitative comments)
- etc…
For most of these examples, there usually is a way for your developers to provide monolingual values in your Data Layer. For instance, monolingual product data or generic URL paths / page names can often be derived from the localization logic of the Content Management System (CMS).
But that is rarely the case for all examples. While the feasibility of course varies from case to case, it ultimately always depends on how much your org wants to spend on developer resources for this problem...
So I usually end up with a good-enough set of monolingual values for the most important dimensions, but the rest remains “Language Salad”. Take a look at these examples:


Now imagine you have 2 hours to analyze which type of content is how engaging, or which parts from the navigation menu could be removed because nobody clicks them. You may be tempted to just filter the data by the language with the most traffic, and then do the analysis only for that language. But that will often lead to wrong conclusions, as people with different linguistic preferences often have different behavioral patterns (e.g., the difference in spending habits of French- vs. German-speaking Swiss users can be breathtaking).
So this is highly unsatisfying.
The Solution, Step 1: What do we need?
Let’s take the Content Tag Language Salad example from above. What we ultimately want is a clean, i.e. “normalized” or “canonicalized”, monolingual Content Tag dimension. Like this one:
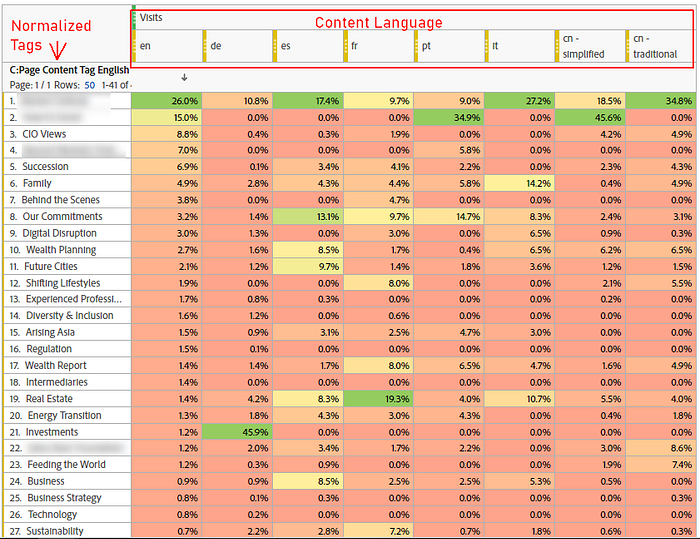
As you can tell, my example uses Adobe Analytics (AA), because AA offers powerful, retroactive data import functionalities (for bottom-line revenue, profit margins and ad cost imports, check out this article by the way).
One of Adobe Analytics’s most useful features are Classifications (called “Lookups” in Customer Journey Analytics, Adobe’s alleged AA successor). Classifications allow you to add any number of additional lookup dimensions based on the “Key” of an existing dimension. Setting the values for these lookup dimensions is called “classifying” or “mapping”. You can classify values via CSV file imports or based on Regular Expression extraction rules. The best thing: They work retroactively. Because you don’t want to classify only future data… 😉
This is roughly what such a Classification CSV import looks like: We have the data from our Language-Salad dimension “Content Tag” (= the Key), and the lookup value (= the Classification), i.e., the normalized Content Tag (= its English equivalent):
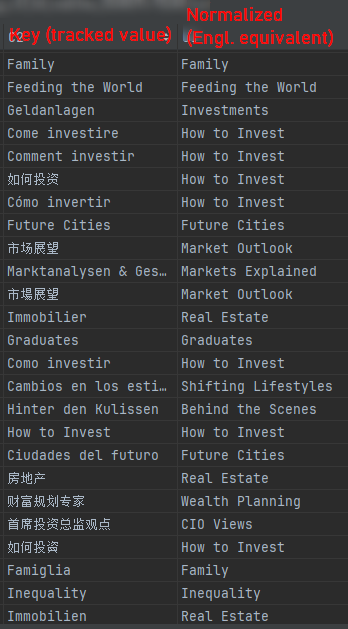
As you can see, the Keys on the left side represent the usual Language Salad. On the right side, we have only normalized (here: English) terms. Much better for analysis.
[Side note: If you use Google Analytics 4, I don’t know any way to accomplish this within the GA4 interface, as the Data Import feature supports only a handful of standard dimensions. But of course, you can reap some of the power by creating a lookup-like table, e.g., in BigQuery and then using that for blended data sources in Looker Studio. Similar for PiwikPro, which unfortunately does not offer any way to import custom data.
Another workaround in these tools would be server-side tracking with a real-time lookup: Before you forward the requests to Analytics, you do a lookup, e.g. via Firestore or Tealium’s Hosted Data Layer. However, this would still only work for new data. Also, previously unknown terms would not be matched because waiting for the LLM to answer queries about new terms before forwarding the request to Analytics would be a resource (and cost) overkill.]
The Solution, Step 2: This is NOT a Translation Task!
So how do we get this normalized English-only column for our Classification import? Is the first thing you are thinking also:
“Just run it through Google Translate/DeepL/Translation API X!”
But you’ll quickly find out:
“That won’t work!”
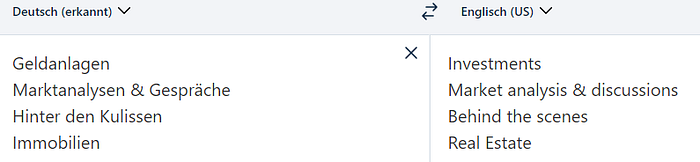
The reason: We would end up with English Term Salad. Not to lash out against the infamous English cuisine again, but that’s not very delicious either. Let’s take a random sample of four German terms from the list and let DeepL translate them to English to simulate what a translation API would do:
Now let’s look at the translation of the French equivalents on that website:
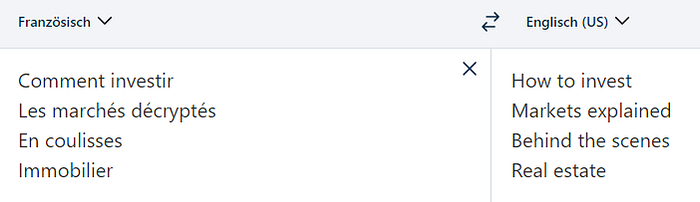
Only 2 of 4 terms match (“Behind the scenes” and “Real estate”) between the translations from French and German. Of course, that is partially because the owners of the website don’t do what many (less customer-oriented) websites do: have some AI translate their entire site word-by-word so they can claim they are a multi-lingual site. Instead, the website in question still employs professional translators who are trying to find better-sounding alternatives in each language: “Geldanlagen” sounds a lot more crisp than if you wrote “Wie investieren”, which would be an ugly word-by-word translation of “How to invest”.
Anyway: Even if the website “employed” translation APIs instead of professional translators, we would still have the same problem. Because the translation API might use English synonym A for the translation from French and synonym B for the translation from German. While it may translate the word German word “Handy” to “mobile phone”, it may translate “téléphone portable” to “cellphone”. Not what we want.
Remember: The goal is not to make each row of the report more readable because the Analyst may not speak Mandarin or French. The goal is to normalize each row into one English equivalent, and one only!
Finally, let’s not forget we are talking about Content Tags, i.e., isolated words without context, so APIs would not know what to do with homonyms (e.g. bow, tear, row) whose meaning depends entirely on the context. You see, I could go on and on about issues with translation APIs… 🥱
Our Choice instead: LLMs
So translation APIs are out. In come LLMs. While until 2022, I associated “LLM” only with the “Master of Laws”, that has shifted due to ChatGPT and other hyped, but definitely useful “Large Language Models”— which, like Crypto, unfortunately also have a ginormous carbon footprint, so I have cut down on using them for fun.
Within Google Cloud Platform (GCP), you can prompt several of Google’s LLMs (e.g., Gemini, formerly known as Bard) from a machine of your own (e.g., from a Python script in a Cloud Function, as we will see later).
Test the waters and understand the tuning wheels
Before writing any code, you should test if the type of task you will give to the LLM will produce a useful response. In the “Vertex AI Studio” interface, you can query Gemini Pro with some advanced features you won’t find in the regular Gemini:
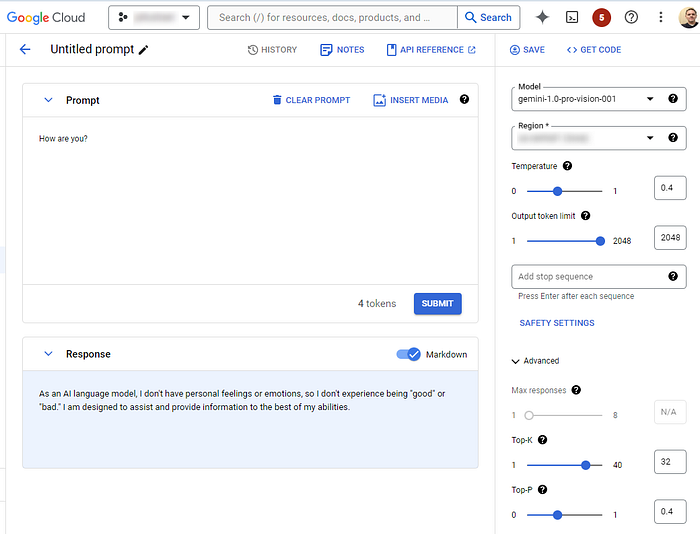
As you may know, LLMs write their answers token-after-token (roughly “word-after-word”). The choice of the next token (think: the next word) is always based on the expectation that that token is the most appropriate next token, given the prompt and the previous tokens. However, to allow for creativity, some randomness is sprinkled in, i.e., the machine does not always select the most appropriate token.
With this principle in mind, we can tune Gemini’s response as follows with the configuration sliders on the right side (I will keep it simple, check out the Vertex AI docs for the details):
- Output token limit: Limits the response to a number of tokens.
- Temperature: The lower, the more deterministic (0 = as little creativity as possible, 1 = very creative). High temperature flattens the probability distribution of the next tokens. E.g., if 3 tokens’ normal probabilities were 0.5 (token1), 0.2 (token2), 0.1 (token3), a high temperature would change that to, e.g., 0.4, 0.3, 0.25).
- Top-K: Ranges from 1–40, where 3 means that only one of the 3 most probable next tokens can be selected (very little creativity), and 40 the opposite.
- Top-P: Ranges from 0–1. Similar to Top-K, but instead of hard-ranking the next tokens, the AI selects from the Top-P percentage of next tokens, based on their cumulative probability. Example: If we have 3 next tokens with probabilities of 0.5 (token1), 0.2 (token2), 0.1 (token3) and our Top-P is 0.65, token1 and token2 will have a chance to be selected because their cumulative probability (0.5 + 0.2) is ≥ 0.65. So a lower Top-P value usually decreases creativity.
Our task is a very deterministic one, as we don’t want the LLM to get creative when classifying. So we use minimum creativity for all values. This does not eliminate hallucinating entirely, but keeps it under control.
We now run the following pipeline regularly (once a day) to accomodate new terms:
#1 Pull Adobe Analytics export of all Content Tags in all languages,
with the corresponding language in a second column. Like this:

In Adobe Analytics, you can accomplish that through the Data Warehouse API or a scheduled Google Cloud Storage export from Data Warehouse.
#2 Get the existing Classifications and create a list of “Source Terms” with only new terms
Asking the LLM excessively can get expensive, and its carbon footprint is a burden to our planet, so we want to limit the number of prompts as much as possible. So instead of asking the LLM to classify all the terms again each time (which also poses the threat of falsely reclassifying sth we have already OK’d in a QA), we only ask it to classify new terms we haven’t classified yet. For this, we need to retrieve the already existing classifications, which we update and store in Cloud Storage after each run.
From these two sources, we can create the delta with only new, unclassified terms. It looks exactly like the Adobe DWH export example above, just shorter. I will now refer to this as the list of “Source Terms”.
#3 Prepare a list of “Target Terms” with all the allowed normalized terms
We have the source terms we want to classify, but we also need to tell our LLM which terms we accept as the result of the classification. In other words, we need to give the LLM a list of all the allowed normalized (English) equivalents, the list of “Target Terms”. Since we know the language of each term from the AA DWH Export, we can filter out only the English terms and add them to an existing list (which we also store in GCS). We then filter out the duplicates and we are ready to go.
We now thus have the lists of source and destination terms. The following illustration shows what we are trying to accomplish based on these:
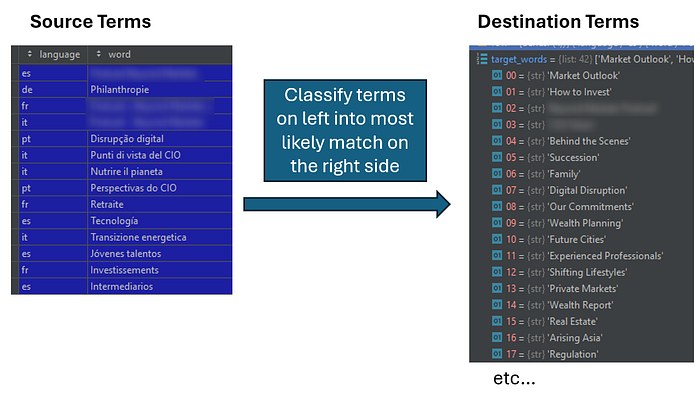
#4 Ask Gemini to classify each term
Now we are ready to get to the core. We can tell Gemini to go to work. In our case, we run all inside of a Google Cloud Function written in Python.
Getting Gemini into a Python script is easier than I thought. You install the google-cloud-aiplatform package, and off you go (assuming you know how to authenticate with GCP from your local device). As you can see in the code example, we can provide the above-mentioned parameters (temperature, top-p, top-k, etc.) to tune the model to our preferences:
from vertexai.preview.generative_models import GenerativeModel
def run_script(prompt: str = None, model: str = "gemini-pro", max_output_tokens: int = 200, temperature: float = 0,
top_p: float = 0, top_k: float = 1):
"""
Generates a response to a given prompt using the Gemini model from Vertex AI.
Parameters:
prompt (str): The input prompt for the model to generate a response to.
model (str): The name of the generative model to use. Default is "gemini-pro".
max_output_tokens (int): The maximum number of output tokens to generate. Default is 200.
temperature (float): The temperature parameter for the model, controlling the randomness of the output. Default is 0.
top_p (float): The top-p parameter for the model, controlling the nucleus sampling. Default is 0.
top_k (float): The top-k parameter for the model, controlling the beam search. Default is 1.
Returns:
str: The generated response text. If no response is generated, returns "empty".
"""
model = GenerativeModel(model)
responses = model.generate_content(
prompt,
generation_config={
"max_output_tokens": max_output_tokens,
"temperature": temperature, # 0 to 1, for all below: higher values = more creativity
"top_p": top_p, # 0 to 1
"top_k": top_k # 1 to 40
},
stream=True
)
# unpack the response which is a "generator" object
responses = [response for response in responses]
# the response text can come in batches, so let's concatenate it
resp_text = ""
for resp in responses:
if hasattr(resp, 'text'):
resp_text += resp.text
if resp_text == "":
return "empty"
return resp_text
if __name__ == "__main__":
_prompt = "What teams did Juwan Howard play for?"
print(f'Asking Gemini for a response to the prompt: "{_prompt}"')
answer = run_script(prompt=_prompt)
print(answer)
# --- Output:
# Asking Gemini for a response to the prompt: "What teams did Juwan Howard play for?"
# * Washington Bullets
# * Miami Heat
# * Dallas Mavericks
# * Denver Nuggets
# * Orlando Magic
# * Portland Trail Blazers
# * Charlotte Hornets
# (as usual, Gemini gets it only 90% right and forgot about the Houston Rockets,
# and the Charlotte Hornets were the Bobcats back then)We can now simply iterate through the list of source terms and ask Gemini to map it to the most likely match on the list of target terms list. Our prompt is ugly and feels redundant. I tried many variations, but this seemed to work best. As for the whole process, I am happy for any improvement suggestions, as this is not my home turf yet:
(f"The expression '{word}' is a term in language '{lang}' or in English. We need to match it "
f"to a normalized term. The list of allowed normalized terms is: '{target_words_str}'. "
f"Your task: Match '{word}' to the most likely normalized term. The result MUST be from the "
f"aforementioned list! If there is no likely match, return 'n/a'. Return only the term from "
f"the list, e.g. 'Market Outlook', NOTHING ELSE!"){word} refers to the source term, {target_words_str} is a semicolon-delimited string of all target terms (semicolon because it could happen that there is a comma in the original terms).
#5 Double-check whether the result makes sense
Remember that LLMs are unreliable (see the Juwan Howard example above) and they produce a lot of nonsense, even with the strictest and most deterministic configurations. As an example, in my test run for this post, it suggested terms that were not among the target terms. So you cannot blindly accept each result, you need some quality control.
In my case, if the result is not among the ones in the destination terms list, I prompt the LLM again up to 3 times, slightly loosening the “creativity constraints” exponentially every time. If the result is still the same, I skip the output:
i = 1
while prompt_result not in target_words:
if i > 3:
log().info(
f"Prompt Result '{prompt_result}' for '{word}' is still not in Target Words after attempt {i}. "
f"Skipping this word.")
skip = True
break
if i > 1:
log().info(
f"Prompt Result '{prompt_result}' for '{word}' not in Target Words after attempt {i - 1}. "
f"Trying again with looser constraints.")
temperature += 0.1 * i
top_p += 0.1 * i
top_k += i * 5
prompt_result = execute_ai_prompt(prompt=prompt_text, temperature=temperature,
max_output_tokens=max_output_tokens, top_p=top_p, top_k=top_k)
i += 1
if skip is True:
continue # we failed, try the next termI do the same by the way if the output is “empty” (when Gemini failed) or “n/a” (when it affirms that it could not find anything).
In the end, we get a table with new classifications like this one where we we were able to map some newer Romance terms:
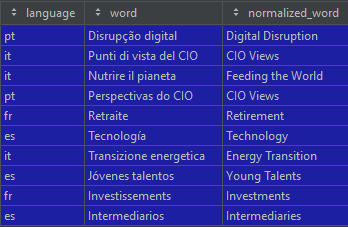
#6 Import the new matches
We can now proceed with our familiar toolbox, i.e., create a Classification CSV Export file from that table for AA and upload it to Cloud Storage from where Adobe will grab and import it swiftly. I will spare you the Classification import details, as that’s the bread and butter of any Adobe admin.
We can then check our Adobe reports. Our Classification dimension (“C:Page Content Tag English”) now shows only beautiful, normalized English terms (yes, same screenshot as in the beginning, I am lazy):
For QA, we can check the original Language-Salad Content Tags for each normalized term. Looks good for Arising Asia (DeepL confirms that 亚洲崛起 means sth like “The Rise of Asia”):
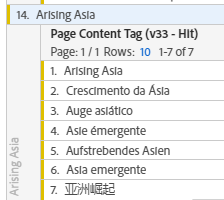
The new normalized dimension makes it much easier to e.g. create language-specific segments, group content or split metrics by Content Tag (e.g. Downloads/Visit Rate or Lead Contribution Rate by Topic). 😃
Limitations
We’re done. Right? Not entirely. There are some limitations:
There are only so many tokens to put into a prompt
There is only so much input text you can give the LLM (and the more tokens, the more expensive), meaning if you have more than just a couple of hundred of destination terms, it won’t work. In this case, try to narrow down the list of allowed terms for a source term, using other context info from your Analytics data (e.g., split limit the terms by sections of the website and then go section-by-section).
You need QA for false matches
Setting the “LSD” aka “creativity” parameters as low as possible helped cut down on hallucination, and the check for “result not among acceptable target terms” eliminated the remaining hallucination cases. Still, there are rare instances when the LLM matches items plausibly, but wrongly. As an example, it mapped “Geldanlagen” to “Investments” and not “How to Invest”. “Investments” is a different Tag for this website, but you can’t blame the LLM to choose that one over “How to Invest”. A human without context would have done the same.
So you need to put some QA in place to spot the gravest of these cases. For this, I check the traffic percentage per normalized term by content language (see report screenshot above). If a certain tag gets an exceptionally high or low traffic share in a particular language, I check for such a misclassification. And as mentioned, the great performance of “Investments” in German was due to such a mismatch.
Some unmatched terms remain
Still, I was never able to match all terms, there were always 3–5% that remained unmatched. If that is important for your use case, put some human on top to map the remaining terms. After all, you spared the humans the dreadful task of mapping 490 terms, so they might even enjoy doing the remaining 10.
Works well for actual words, less well for URLs etc.
Words are a grateful example, because the LLM works well there. I also tried it on links in various languages to make a header navigation click-through report easier (instead of adding up the values of “/contact/form”, “/kontakt/formular” etc…, I want a single report line). Here, the error & fail rate is higher, and I need additional steps (split out the individual levels of the URL (contact, form, etc.), then map those, then put all parts together afterwards again to get to an acceptable match rate).
Suggestions? Opinions? Tell me!
This is my first try to bring benefits from LLMs to classic Web Analytics solutions. What did I miss? What should I do differently? Any suggestions are appreciated.
Thanks for reading! And do subscribe to get my new articles right into your mailbox. No Medium paywall. ;)

